
|
|

芯东西4月6日消息,昨日,据福布斯报道,全球机器学习工程联盟MLCommons基于权威AI基准评测MLPerf 3.0发布最新测试结果,美国人工智能训练芯片巨头英伟达又一次在性能对比中超越竞争对手。
英伟达及其合作伙伴在MLPerf 3.0中运行并提交了基准测试,包括图像分类、对象检测、推荐、语音识别、NLP(自然语言处理)和3D分割。英伟达指出,许多客户要一个多功能的AI(人工智能)平台,该平台一般适用于数据中心环境,许多像图像分类或检测的边缘AI应用仅使用一种或两种AI模型。
这一轮MLPerf的新测试成员分别是致力于边缘图像分类和数据中心的美国机器学习初创公司SiMa.ai和美国AI解决方案提供创企Neuchips。

虽然目前没有针对(超)大型语言模型(例如GPT或LaMDA)的基准,但MLCommons执行董事David Kanter说,MLCommons正在制定一个新的基准,该基准将测试最近AI领域的一亿级参数模型的训练、性能和功耗。即使测试结果还要等待六个月,当前的BERT基准对于评估从GPT-3等模型中提取的较小型语言模型的平台仍然很有用。英伟达H100拥有一个在MLPerf 3.0基准测试中主导BERT的Transformer引擎。
英伟达在其最新产品H100、L4和Jetson AGX Orin上运行基准测试。虽然英伟达2周前在GTC上宣布的H100 NVL并不在此次测试范围内,但预计H100 NVL对运行像ChatGPT这样的大型模型推理性能或许仍就保持在较高水平。
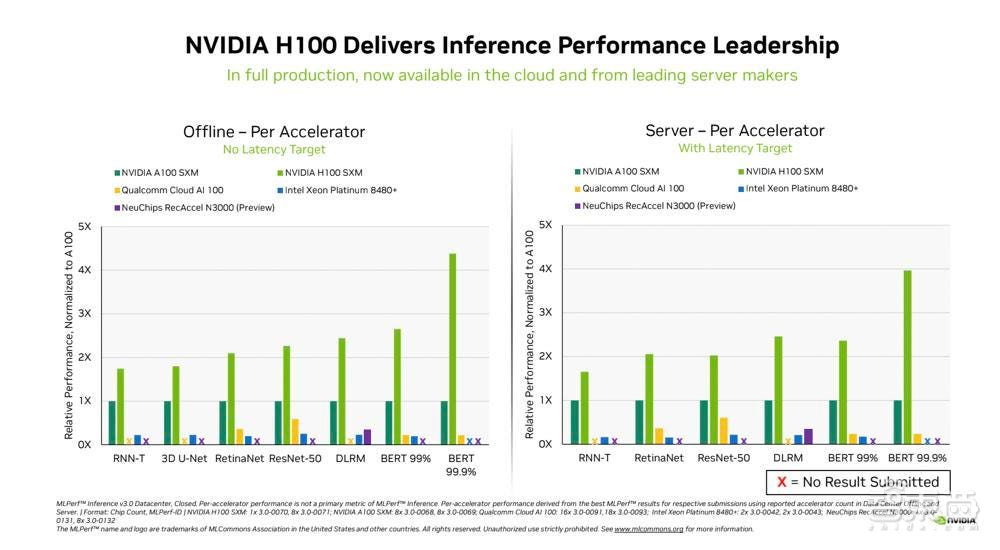
与往常一样,英伟达运行了所有MLPerf基准测试,包括利用互联网将模型数据提供给服务器,而不是将参数加载到系统中的新网络模型。英伟达H100 Tensor Core GPU在每次AI推理测试中都展现出最高性能。得益于软件优化,该GPU的性能比去年9月份首次亮相时提高了54%。英伟达拥有比硬件工程师更多的软件工程师是有原因的。
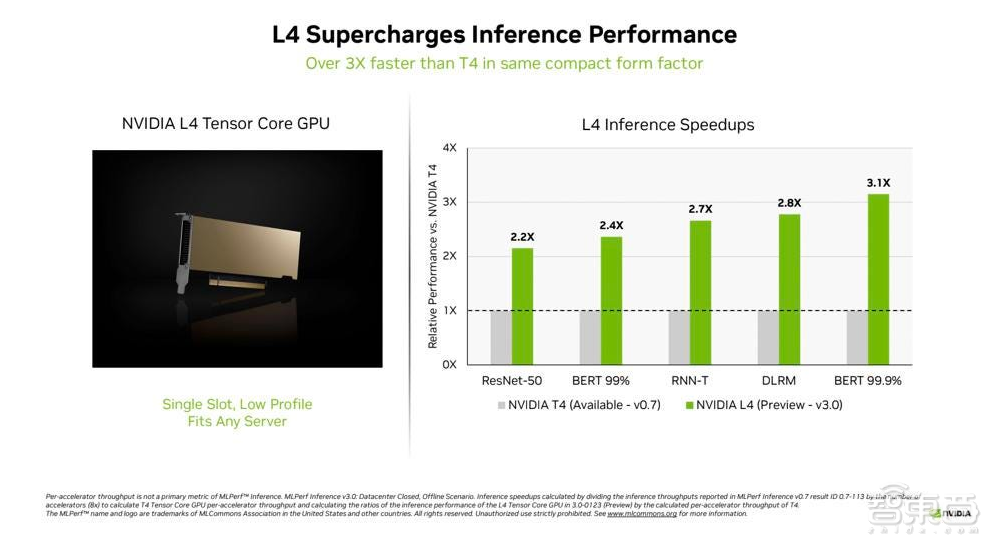
新的英伟达L4 Tensor Core GPU在MLPerf测试中首次亮相,其速度是上一代T4 GPU的3倍以上。跟着时间的推移,更新的软件在性能提升方面发挥着及其重要的作用。L4 Tensor Core GPU采用PCIe接口,可运行所有MLPerf工作任务,符合英伟达的理念,即客户要一个多功能且灵活的AI平台。这些GPU支持FP8格式,这对于其在BERT NLP模型上获得最佳性能至关重要。
在对性能要求高的边缘AI芯片市场,英伟达芯片测试的结果排名仍然位于前列。与一年前的结果相比,英伟达Jetson AGX Orin系统级模块的能效提高了63%,性能提高了81%。Jetson AGX Orin可在密闭空间以低功率水平(包括电池供电的系统)为AI需求提供推理。

以色列机器学习初创公司Deci为美国电脑软件公司Adobe等企业来提供ML(机器学习)优化服务。Deci所做的有点类似于美国EDA领导者Synopsys(新思科技)为改进芯片设计所做的工作,Deci应用AI来优化给定模型、数据和目标运行时芯片的AI模型。
Deci在英伟达A30、A100和H100 GPU上提供了最佳的自然语言处理(NLP)吞吐量效率,优于BERT中绝大多数的其它测试者。Deci在A100上的吞吐量比英伟达H100 GPU上的其他结果高出1.7倍。这在某种程度上预示着ML团队能节约大约68%的推理成本,同时提高模型的速度和准确性。且该优化过程是自动的,并有硬件合作伙伴包括英伟达、英特尔、亚马逊云科技,以及许多系统供应商,如HPE等客户公司证明优化过程确实有效。
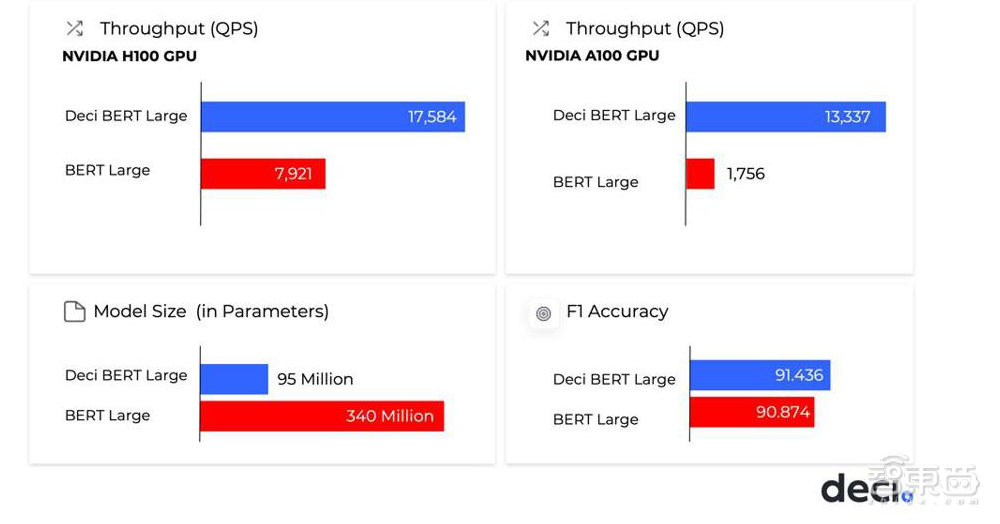
▲Deci为英伟达 A100、H100 GPU提供出色的模型优化(图源:福布斯)
虽然英伟达GPU提供了行业领先的性能,但这种性能领先除了高昂的购买成本外还需要付出功耗的代价。功率对于边缘推理很重要,美国人工智能边缘数据中心和无线电融信研发技术公司Qualcomm(高通)和嵌入式AI边缘计算创企SiMa.ai都重视减少功耗。尽管二者都涉及“边缘”业务,但这两家公司并没有真正的竞争关系。SiMa.ai的产品副总裁Gopal Hegde说:“我们从未在任何潜在对手中遇到过高通。”
高通的Cloud AI100为超过25个服务器平台提交了320个结果,在同种类型的产品中的能效、延迟和吞吐量方面均处于业界最佳水平。跟着时间的推移,软件优化的重要性得到了证明,自3年前开始这一旅程以来,高通的芯片已经实现了75%的性能和52%的能效提升。面对高通的性能提升,有关人员希望SiMa能够在每次发布TVM后端软件时也能逐步的提升性能。
MLPerf 3.0结果包括开放任务的新基准、利用互联网进行模块修剪的BERT Large,其准确率达到100%,性能比其封闭部门提交的高2.8倍。MLPerf的开放业务允许所有类型的技巧和更改,只要达到准确度即可。

SiMa.ai专注于智能视觉、机器人、制造、无人机或汽车等应用的嵌入式边缘AI。嵌入式边缘AI的目标是使这些设备能够在本地执行复杂的数据处理和分析,而无需将数据发送到远程服务器或云做处理。这能大大的提升数据处理的速度和效率,减少延迟,并实现实时决策。
嵌入式边缘人工智能的一些例子包括能够理解和响应用户命令的语音助手、可以检测异常和触发警报的传感器,以及可以实时识别和响应周围环境的无人驾驶汽车。
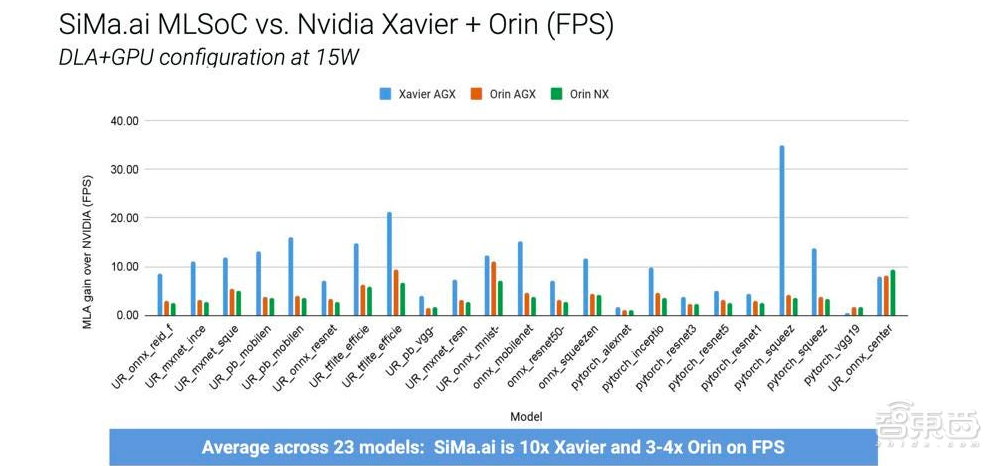
为了实现用户的电力需求,SiMa.ai必须从头开始设计边缘AI芯片,缩小数据中心中AI芯片的规模是行不通的。因此SiMa.ai从头开始将MLSoC芯片构建为嵌入式平台。在MLPerf 3.0第一轮性能测试中,SiMa.ai在图像分类方面比英伟达Jetson AGX Orin能效高出47%。
英伟达再一次在性能上获胜,但在边缘数据中心和嵌入式边缘等功率受限场景中面临着日益激烈的竞争,高通和SiMa.ai在这些场景中取得了胜利。英伟达拥有的软件工程师数量远超于许多竞争对手的员工数量,而且这些工程师继续为每一代芯片中提升更多性能,尤其是在数据中心和需要灵活运行许多模型的边缘应用程序中。
值得注意的是,亚马逊云计算芯片、AMD数据中心GPU(如Instinct MI250)、谷歌TPU、特斯拉和英特尔的AI芯片都没再次出现在MLPerf 3.0测试名单中,初创公司Cerebras、Graphcore、Groq和Samba Nova也是如此。我们很难想象这一些企业对展示他们在最新硬件上运行最新模型的表现不感兴趣。
那么,如何让这些供应商也对这一测试产生兴趣呢?一种可能的方法是通过新的MLCommons集体知识挑战让社区运行和提交基准、模型和学习,以运行、复制和优化由cTuning基金会和cKnowledge Ltd领导的MLPerf推理v3.0基准。
如果这一策略奏效,并且随着TPU、亚马逊云计算芯片和AMD等新芯片的后端实现,消费者能在有效的测试比较中看到这些边缘AI技术的爆炸式增长,这对于使用AI技术的全用户和购买者是有利的。
在六个月后的VLLM基准竞赛中,也许现在与ChatGPT和新的CK playground及其竞争对手一起摆在桌面上的巨额资金将使更多公司的硬件产品性能变得更清晰。
作为全球权威的AI基准评测MLPerf 3.0,其每隔6个月发布的各大AI公司产品性能评测结果受到业内人士广泛关注。根据此次推理基准测试结果,英伟达H100 GPU、L4 Tensor Core GPU、Jetson AGX Orin在性能、速度和能效上均表现优异,在至关重要的AI训练芯片市场,英伟达仍保持其领导地位。
值得关注的是,以色列机器学习初创公司Deci和美国机器学习初创公司SiMa.ai在此次测试中表现出不逊色的实力,Deci优秀自然语言处理吞吐量效率提高了AI模型的速度和准确性,节省了推理成本,SiMa.ai在图像分类领域具有强大的低功耗性能。这些机器学习创企的技术进步推动着边缘AI模型应用的发展。


